欢迎光临~湖南智能应用科技有限公司-hniat.com
语言选择:
 ∷
∷

∷
 ∷
∷
从4月中旬开始深度学习之旅,到现在已经逐渐对神经网络有了一些初步的认识,选择tensorflow框架进行深度学习时,刚开始或许不太适应这种graph形式,但是tensorflow也在一定程度上帮助我们更好地理解神经网路的框架。
谨以此文来鼓励在劳动节还依然坚持学习的自己。
1.目标:建立一个纯数字验证码识别器
2.原理:CNN
3.工具:Tensorflow
4.意义:熟悉tensorflow框架,推导前向传播过程,促进CNN的理解
训练数据和测试数据均来自于 captcha.image库中的ImageCaptcha类。
ImageCaptcha可以根据输入的文本生成相应的验证码图片
由于时第一次处理图像数据,所以前期大部分功夫还是以图像预处理为主
首先写一个脚本,测试一下文本验证码和图片验证码的获取
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt from PIL import Image import random #载入数据集 from captcha.image import ImageCaptcha number = ['0','1','2','3','4','5','6','7','8','9'] alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'] ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']
将以上数字和字母随机组合在一起,生成一个验证码,验证码的长度为4,总共有62*62*62*62种不同的label
#定义一个random_captcha_text函数,每调用一次就会生成一个验证码,其组成元素存放在一个列表中
def random_captcha_text(char_set=number+alphabet+ALPHABET, captcha_size=4):
captcha_text = []
for i in range(captcha_size): #循环取四次
x = random.choice(char_set) #random.choice随机选区一个元素
captcha_text.append(x)
return captcha_text
#将构成验证码的元素与图片相对应,从captcha.image库中获得相应的图片
def get_captcha_text_and_image():
#调用ImageCaptcha类,用来生成验证码图片
image = ImageCaptcha()
#用random_captcha_text()函数得到四个元素
captcha_text = random_captcha_text()
#将四个元素连接在一起,组成一个完整的验证码
captcha_text = ''.join(captcha_text)
#根据生成的文本验证码得到相应的图片验证码
captcha = image.generate(captcha_text)
#打开图片,PIL.Image.open()专接图片路径,用来直接读取该路径指向的图片
captcha_image = Image.open(captcha)
#将图片转化为array格式
captcha_image = np.array(captcha_image)
return captcha_text,captcha_image
最后测试一下数据是否正确
if __name__ == '__main__':
text, image = get_captcha_text_and_image()
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9,text, ha='center', va='center', transform=ax.transAxes)
plt.imshow(image)
plt.show()
生成结果如上所示,符合预期的结果
基于时间成本的考虑,此次实战只训练纯数字组成的识别器
根据数据采集的结果来看,生成的验证码图片是彩色图,且有shape命令可知,其维度是60*160*3,因此我们首先得进行预处理,主要报概括:
2. 将图片转化为数组的形式——降维操作
3. 将文本型的验证码(eg:4123)转化为向量——类似于编码,每一位验证码有10各类别,正确类比为1,其余 均为0
补充: 将向量型的验证码转化为文本,最后测试阶段的得到的时向量型的验证码,所以要转化为文本
import numpy as np
import tensorflow as tf
from captcha.image import ImageCaptcha
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import random
# 图像大小
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
MAX_CAPTCHA = 4 #验证码最大长度为4
CHAR_SET_LEN = 10 #验证码的每一位有10个类别
checkpoint_dir = '' #用来保存模型的路径
number = ['0','1','2','3','4','5','6','7','8','9']
#将以上数字和字母随机组合在一起,生成一个验证码,验证码的长度为4,总共有10*10*10*10种不同的label
#定义一个random_captcha_text函数,每调用一次就会生成一个验证码,其组成元素存放在一个列表中
def random_captcha_text(char_set=number, captcha_size=4):
captcha_text = []
for i in range(captcha_size): #循环取四次
x = random.choice(char_set) #random.choice随机选区一个元素
captcha_text.append(x)
return captcha_text
#将构成验证码的元素与图片相对应,从captcha.image库中获得相应的图片
def gen_captcha_text_and_image():
#调用ImageCaptcha类,用来生成验证码图片
image = ImageCaptcha()
#用random_captcha_text()函数得到四个元素
captcha_text = random_captcha_text()
#将四个元素连接在一起,组成一个完整的验证码
captcha_text = ''.join(captcha_text)
#根据生成的文本验证码得到相应的图片验证码
captcha = image.generate(captcha_text)
#打开图片,PIL.Image.open()专接图片路径,用来直接读取该路径指向的图片
captcha_image = Image.open(captcha)
#将图片转化为array格式
captcha_image = np.array(captcha_image)
return captcha_text,captcha_image
#将图片转化为2维的灰度图
def convert2gray(imag_):
if len(imag_.shape) > 2:
gray = np.mean(imag_, -1) #按照最后一个维度求均值
return gray
else:
return imag_
#将文本转化为向量
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError #('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
for key,val in enumerate(text): #enumerate(text)同时返回列表的索引和值
idx = key * 10 + int(val)
vector[idx] = 1
return vector
#将向量转化为文本
def vev2text(vec):
text=[]
char_pos = vec.nonzero()[0] #np.nonzero返回非零值的索引
for i in enumerate(char_pos):
number = i % 10 #通过取余数的办法获得数字值
text.append(str(number))
return "".join(text)
最后我们调用定义好的函数来生成一个batch
#生成一个训练batch
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT*IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA*CHAR_SET_LEN])
#有时生成图像大小不是(60, 160, 3)
def wrap_gen_captcha_text_and_image():
''' 获取一张图,判断其是否符合(60,160,3)的规格'''
while True:
text, image = gen_captcha_text_and_image()
if image.shape == (60, 160, 3):
return text, image
for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image()
image = convert2gray(image)
#将图片数组一维化,即扁平化,再将像素点压缩在0~1之间
batch_x[i,:] = image.flatten() / 255 # (image.flatten()-128)/128 mean为0
#同时将文本也对应同时将文本也对应在两个二维组的同一行
batch_y[i,:] = text2vec(text)
return batch_x, batch_y
此次训练我们建立三个卷积-池化层,最后用两个全连接层:
输入层:一张图片的大小是60*160,深度为1,所以n_input=60*160
第一层卷积:32个filter,每个filter的大小为3*3*1,步长为1,padding为1,卷积得到的feature_map的高为为(60-3+2)/1+1=60,宽也没变,所以最终得到的是32个60*160*32的feature map
第一层池化:将32个特征图进行max pooling,池化层的大小为2*2,步长为2,池化后的高为60/2=30,宽为160/2=80所以最终得到的是30*80*32的feature map
第二层卷积:64个filter,每个filter的大小为3*3*32,步长为1,padding为1,卷积后的宽高不变 ,所以最终得到的是30*80*64的feature map
第二层池化:进行2*2的max pooling,步长为2,最终得到的是15*40*64的feature map
第三层卷积:64个filter,每个filter的大小为3*3*64,步长为1,padding为1,卷积后的宽高不变,所以最终得到的是15*40*64的feature map
第三层池化:进行2*2的max pooling,步长为2最终得到的是8*20*64的feature map
第一层全链接:设置1024个神经元,与前面的池化层相连接,则维度是1024,大小为(8*20*64,1024)
第二层全连接(输出层):最终输出40分类的概率,所以其维度为1024*40
对于CNN网络框架的建立,个人理解是最好是画一个图,这样更直观一点。下面开始前向传播,这里引入了w_alpha=0.01, b_alpha=0.1产生噪点
#占位
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
#正向传播:
#参数的初始化过程中需要加入一小部分的噪声以破坏参数整体的对称性,同时避免梯度为0,即w_alpha=0.01, b_alpha=0.1
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
#对输入的图像进行预处理:转换为tensorflow支持的格式:
#[batch, in_height, in_width, in_channels] ,-1表示自动计算
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
#strides为步长,格式为:[filter_height, filter_width, in_channels, out_channels]
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32]))
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha*tf.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha*tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
# Fully connected layer
w_d = tf.Variable(w_alpha*tf.random_normal([8*20*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha*tf.random_normal([1024, MAX_CAPTCHA*CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha*tf.random_normal([MAX_CAPTCHA*CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
return out
接着建立反向传播的框架,主要包含损失函数、优化器和精确度的计算。这里将模型的保存也包含在其中,由于此次项目在笔记本上完成,计算效率很低。所以将精度的阈值设置为40%
# 反向传播
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
#损失函数
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output,labels=Y))
#优化器:
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
#将最终的输出值转化为三维数组,高为4,宽为10,第三个维度(batch)自动计算,
#每个二维数组的每一行就代表验证码每一位数字10各类别的概率值
predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
#按照第三个维度索取每一个二维数组取得最大值的索引
max_idx_p = tf.argmax(predict, 2)
#同时对真实值Y也索取其最大值的索引
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
#计算精确度
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
#存储训练的数据
saver = tf.train.Saver(max_to_keep=1)
#创建计算视图
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#max_acc = 0
step = 0
#用while循环迭代,直到精确度大于某一阈值,用for循环可以找到规定循环次数内的最高精度
while True:
#每次训练选取128个样本
batch_x, batch_y = get_next_batch(128)
_, loss_ = sess.run([optimizer, loss], feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.75})
# 每10 step计算一次准确率
if step % 10 == 0:
#每次选取128个样本用来验证
batch_x_test, batch_y_test = get_next_batch(128)
acc = sess.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 1.})
print(step, acc)
#当精确度高于55%时就保存模型
if acc > 0.40:
saver.save(sess, checkpoint_dir + 'model.ckpt', global_step=step)
break
step += 1
最后还需要定义一个函数,相当于模型的提取,或者称为训练好的识别器,在最终测试识别阶段将图片放入框架中计算,得到最终的预测文本,其实也可以写在写一部分:
#定义crack_captcha用来最后识别验证码的文本:
def crack_captcha(captcha_image):
#最后的识别只经过正向传播,先建立一个框架
output = crack_captcha_cnn()
#调取保存的模型参数
saver = tf.train.Saver()
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
saver.restore(sess, ckpt.model_checkpoint_path)
#将预测结果预处理,先变成维向量(1*4*10),再求出其每一行的最大索引,即为验证码数字
predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
#进行预测,不要dropout
text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1})
#这里返回的是索引矩阵,好需要将其转化为列表---tolist()
text = text_list[0].tolist()
#最后得到的就是识别出来的验证码
return text
训练和测试放在一起,可以用一个变量来进行控制:
train = 0 #用来控制是训练还是测试:
#训练:
if train == 0:
number = ['0','1','2','3','4','5','6','7','8','9']
text, image = gen_captcha_text_and_image()
#占位
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
#开始正向+反向传播:
train_crack_captcha_cnn()
#测试:
if train == 1:
text, image = gen_captcha_text_and_image()
#绘制验证码图片
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9,text, ha='center', va='center', transform=ax.transAxes)
plt.imshow(image)
plt.show()
#将图片进行预处理
image = convert2gray(image)
image = image.flatten() / 255
#占位
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT*IMAGE_WIDTH])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
keep_prob = tf.placeholder(tf.float32) # dropout
#将图片放入模型进行识别:
predict_text = crack_captcha(image)
print("正确: {} 预测: {}".format(text, predict_text))
至此,一个简单的验证码识别器就编写完毕。接下来就是等待漫长的训练,差不多花了2小时左右吧,最后的效果如下所示:
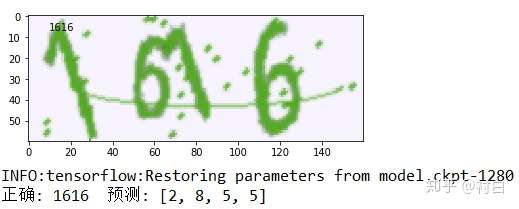
emmmm......嘛.。毕竟精确度只有40%。。。可怜一下CPU计算的孩子吧。。。

3. 从4月1好开始机器学习,到今天刚满一个月,除了周末上班以外基本保持着每天5-12小时的学习。迷茫过也放弃过。不过在月末的时候拿了几个offer已经很满足了。就像当出考研一样,只要坚持下去,三个月,一定会有收获
4. 其实自己对于之前的机器学习知识掌握的还不是特别熟练,5月份的任务大概是:复习+深度学习(计算机视觉)
联系人:徐经理
手机:13907330718
电话:0731-22222718
邮箱:hniatcom@163.com
地址: 湖南省株洲市石峰区联诚路79号轨道智谷2号倒班房6楼603室
 湖南智能-MSN
湖南智能-MSN 湖南智能-Skype
湖南智能-Skype
 湖南智能-阿里
湖南智能-阿里