欢迎光临~湖南智能应用科技有限公司-hniat.com
语言选择:
 ∷
∷

∷
 ∷
∷
人工智能是人类一个非常美好的梦想,跟星际漫游和长生不老一样。我们想制造出一种机器,使得它跟人一样具有一定的对外界事物感知能力,比如看见世界。
在上世纪50年代,数学家图灵提出判断机器是否具有人工智能的标准:图灵测试。即把机器放在一个房间,人类测试员在另一个房间,人跟机器聊天,测试员事先不知道另一房间里是人还是机器 。经过聊天,如果测试员不能确定跟他聊天的是人还是机器的话,那么图灵测试就通过了,也就是说这个机器具有与人一样的感知能力。
但是从图灵测试提出来开始到本世纪初,50多年时间有无数科学家提出很多机器学习的算法,试图让计算机具有与人一样的智力水平,但直到2006年深度学习算法的成功,才带来了一丝解决的希望。
深度学习在很多学术领域,比非深度学习算法往往有20-30%成绩的提高。很多大公司也逐渐开始出手投资这种算法,并成立自己的深度学习团队,其中投入最大的就是谷歌,2008年6月披露了谷歌脑项目。2014年1月谷歌收购DeepMind,然后2016年3月其开发的Alphago算法在围棋挑战赛中,战胜了韩国九段棋手李世石,证明深度学习设计出的算法可以战胜这个世界上最强的选手。
在硬件方面,Nvidia最开始做显示芯片,但从2006及2007年开始主推用GPU芯片进行通用计算,它特别适合深度学习中大量简单重复的计算量。目前很多人选择Nvidia的CUDA工具包进行深度学习软件的开发。
微软从2012年开始,利用深度学习进行机器翻译和中文语音合成工作,其人工智能小娜背后就是一套自然语言处理和语音识别的数据算法。
百度在2013年宣布成立百度研究院,其中最重要的就是百度深度学习研究所,当时招募了著名科学家余凯博士。不过后来余凯离开百度,创立了另一家从事深度学习算法开发的公司地平线。
Facebook和Twitter也都各自进行了深度学习研究,其中前者携手纽约大学教授Yann Lecun,建立了自己的深度学习算法实验室;2015年10月,Facebook宣布开源其深度学习算法框架,即Torch框架。Twitter在2014年7月收购了Madbits,为用户提供高精度的图像检索服务。
互联网巨头看重深度学习当然不是为了学术,主要是它能带来巨大的市场。那为什么在深度学习出来之前,传统算法为什么没有达到深度学习的精度?
在深度学习算法出来之前,对于视觉算法来说,大致可以分为以下5个步骤:特征感知,图像预处理,特征提取,特征筛选,推理预测与识别。早期的机器学习中,占优势的统计机器学习群体中,对特征是不大关心的。
我认为,计算机视觉可以说是机器学习在视觉领域的应用,所以计算机视觉在采用这些机器学习方法的时候,不得不自己设计前面4个部分。
但对任何人来说这都是一个比较难的任务。传统的计算机识别方法把特征提取和分类器设计分开来做,然后在应用时再合在一起,比如如果输入是一个摩托车图像的话,首先要有一个特征表达或者特征提取的过程,然后把表达出来的特征放到学习算法中进行分类的学习。
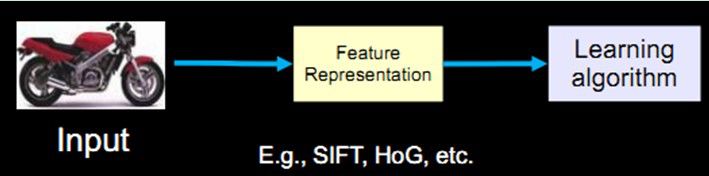
过去20年中出现了不少优秀的特征算子,比如最著名的SIFT算子,即所谓的对尺度旋转保持不变的算子。它被广泛地应用在图像比对,特别是所谓的structure from motion这些应用中,有一些成功的应用例子。另一个是HoG算子,它可以提取物体,比较鲁棒的物体边缘,在物体检测中扮演着重要的角色。
这些算子还包括Textons,Spin image,RIFT和GLOH,都是在深度学习诞生之前或者深度学习真正的流行起来之前,占领视觉算法的主流。
这些特征和一些特定的分类器组合取得了一些成功或半成功的例子,基本达到了商业化的要求但还没有完全商业化。
一是八九十年代的指纹识别算法,它已经非常成熟,一般是在指纹的图案上面去寻找一些关键点,寻找具有特殊几何特征的点,然后把两个指纹的关键点进行比对,判断是否匹配。
然后是2001年基于Haar的人脸检测算法,在当时的硬件条件下已经能够达到实时人脸检测,我们现在所有手机相机里的人脸检测,都是基于它或者它的变种。
第三个是基于HoG特征的物体检测,它和所对应的SVM分类器组合起来的就是著名的DPM算法。DPM算法在物体检测上超过了所有的算法,取得了比较不错的成绩。
但这种成功例子太少了,因为手工设计特征需要大量的经验,需要你对这个领域和数据特别了解,然后设计出来特征还需要大量的调试工作。说白了就是需要一点运气。
另一个难点在于,你不只需要手工设计特征,还要在此基础上有一个比较合适的分类器算法。同时设计特征然后选择一个分类器,这两者合并达到最优的效果,几乎是不可能完成的任务。
如果不手动设计特征,不挑选分类器,有没有别的方案呢?能不能同时学习特征和分类器?即输入某一个模型的时候,输入只是图片,输出就是它自己的标签。比如输入一个明星的头像,出来的标签就是一个50维的向量(如果要在50个人里识别的话),其中对应明星的向量是1,其他的位置是0。
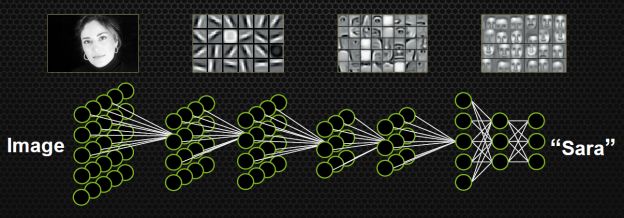
这种设定符合人类脑科学的研究成果。
1981年诺贝尔医学生理学奖颁发给了David Hubel,一位神经生物学家。他的主要研究成果是发现了视觉系统信息处理机制,证明大脑的可视皮层是分级的。他的贡献主要有两个,一是他认为人的视觉功能一个是抽象,一个是迭代。抽象就是把非常具体的形象的元素,即原始的光线像素等信息,抽象出来形成有意义的概念。这些有意义的概念又会往上迭代,变成更加抽象,人可以感知到的抽象概念。
像素是没有抽象意义的,但人脑可以把这些像素连接成边缘,边缘相对像素来说就变成了比较抽象的概念;边缘进而形成球形,球形然后到气球,又是一个抽象的过程,大脑最终就知道看到的是一个气球。
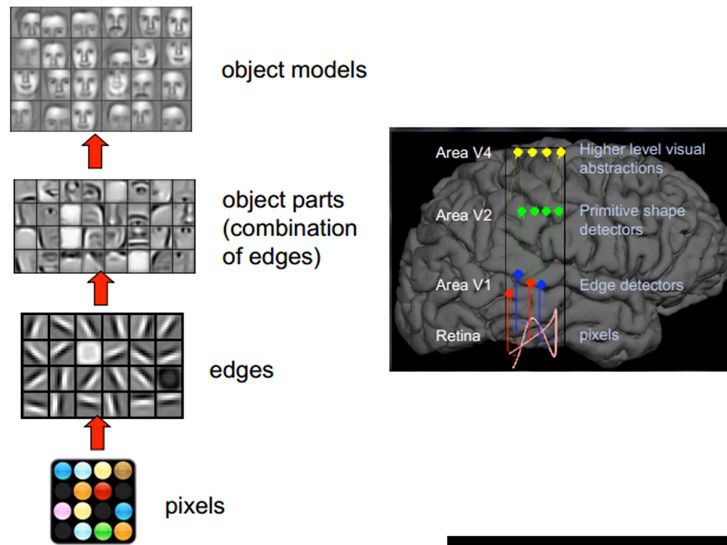
模拟人脑识别人脸,也是抽象迭代的过程,从最开始的像素到第二层的边缘,再到人脸的部分,然后到整张人脸,是一个抽象迭代的过程。
再比如看到图片中的摩托车,我们可能在脑子里就几微秒的时间,但是经过了大量的神经元抽象迭代。对计算机来说最开始看到的根本也不是摩托车,而是RGB图像三个通道上不同的数字。
所谓的特征或者视觉特征,就是把这些数值给综合起来用统计或非统计的形式,把摩托车的部件或者整辆摩托车表现出来。深度学习的流行之前,大部分的设计图像特征就是基于此,即把一个区域内的像素级别的信息综合表现出来,利于后面的分类学习。
如果要完全模拟人脑,我们也要模拟抽象和递归迭代的过程,把信息从最细琐的像素级别,抽象到“种类”的概念,让人能够接受。
计算机视觉里经常使卷积神经网络,即CNN,是一种对人脑比较精准的模拟。
什么是卷积?卷积就是两个函数之间的相互关系,然后得出一个新的值,他是在连续空间做积分计算,然后在离散空间内求和的过程。实际上在计算机视觉里面,可以把卷积当做一个抽象的过程,就是把小区域内的信息统计抽象出来。
比如,对于一张爱因斯坦的照片,我可以学习n个不同的卷积和函数,然后对这个区域进行统计。可以用不同的方法统计,比如着重统计中央,也可以着重统计周围,这就导致统计的和函数的种类多种多样,为了达到可以同时学习多个统计的累积和。
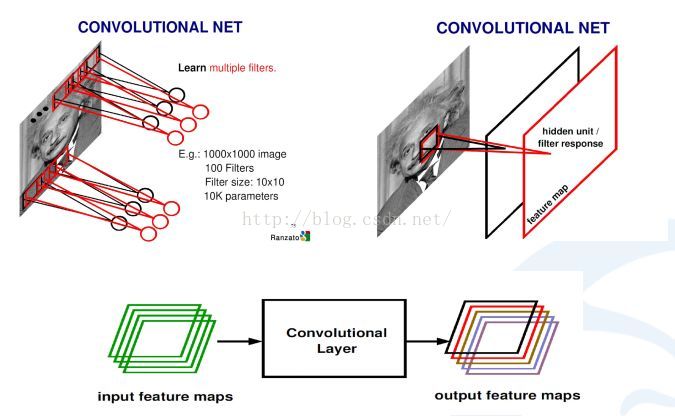
上图中是,如何从输入图像怎么到最后的卷积,生成的响应map。首先用学习好的卷积和对图像进行扫描,然后每一个卷积和会生成一个扫描的响应图,我们叫response map,或者叫feature map。如果有多个卷积和,就有多个feature map。也就说从一个最开始的输入图像(RGB三个通道)可以得到256个通道的feature map,因为有256个卷积和,每个卷积和代表一种统计抽象的方式。
在卷积神经网络中,除了卷积层,还有一种叫池化的操作。池化操作在统计上的概念更明确,就是一个对一个小区域内求平均值或者求最大值的统计操作。
带来的结果是,如果之前我输入有两个通道的,或者256通道的卷积的响应feature map,每一个feature map都经过一个求最大的一个池化层,会得到一个比原来feature map更小的256的feature map。
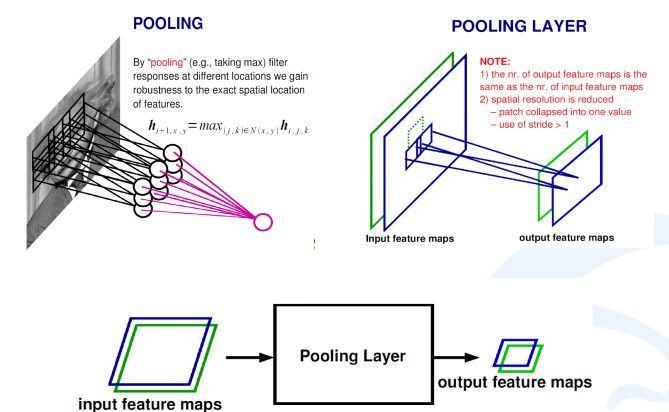
在上面这个例子里,池化层对每一个2X2的区域求最大值,然后把最大值赋给生成的feature map的对应位置。如果输入图像是100×100的话,那输出图像就会变成50×50,feature map变成了一半。同时保留的信息是原来2X2区域里面最大的信息。
Le顾名思义就是指人工智能领域的大牛Lecun。这个网络是深度学习网络的最初原型,因为之前的网络都比较浅,它较深的。LeNet在98年就发明出来了,当时Lecun在AT&T的实验室,他用这一网络进行字母识别,达到了非常好的效果。
怎么构成呢?输入图像是32×32的灰度图,第一层经过了一组卷积和,生成了6个28X28的feature map,然后经过一个池化层,得到得到6个14X14的feature map,然后再经过一个卷积层,生成了16个10X10的卷积层,再经过池化层生成16个5×5的feature map。
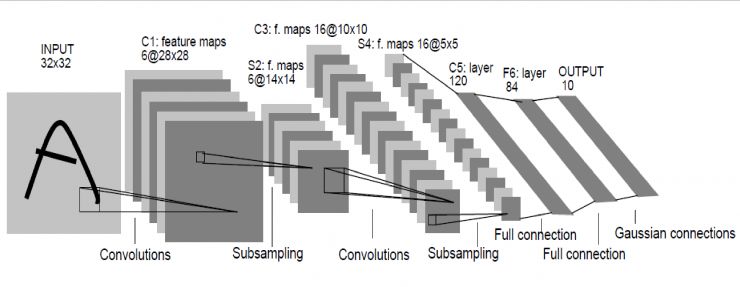
从最后16个5X5的feature map开始,经过了3个全连接层,达到最后的输出,输出就是标签空间的输出。由于设计的是只要对0到9进行识别,所以输出空间是10,如果要对10个数字再加上26个大小字母进行识别的话,输出空间就是62。62维向量里,如果某一个维度上的值最大,它对应的那个字母和数字就是就是预测结果。
从98年到本世纪初,深度学习兴盛起来用了15年,但当时成果泛善可陈,一度被边缘化。到2012年,深度学习算法在部分领域取得不错的成绩,而压在骆驼身上最后一根稻草就是AlexNet。
AlexNet由多伦多大学几个科学家开发,在ImageNet比赛上做到了非常好的效果。当时AlexNet识别效果超过了所有浅层的方法。此后,大家认识到深度学习的时代终于来了,并有人用它做其它的应用,同时也有些人开始开发新的网络结构。
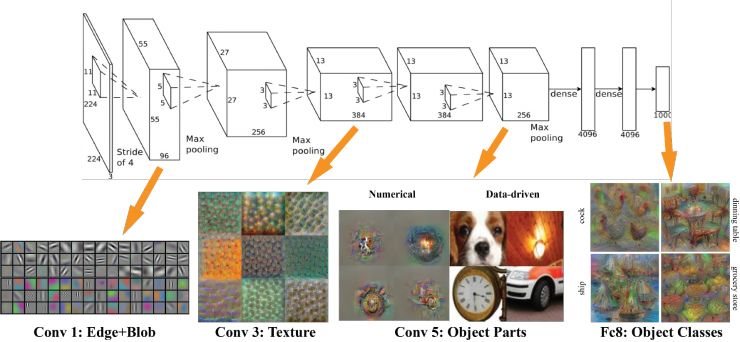
其实AlexNet的结构也很简单,只是LeNet的放大版。输入是一个224X224的图片,是经过了若干个卷积层,若干个池化层,最后连接了两个全连接层,达到了最后的标签空间。
去年,有些人研究出来怎么样可视化深度学习出来的特征。那么,AlexNet学习出的特征是什么样子?在第一层,都是一些填充的块状物和边界等特征;中间的层开始学习一些纹理特征;更高接近分类器的层级,则可以明显看到的物体形状的特征。
最后的一层,即分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
可以说,不论是对人脸,车辆,大象或椅子进行识别,最开始学到的东西都是边缘,继而就是物体的部分,然后在更高层层级才能抽象到物体的整体。整个卷积神经网络在模拟人的抽象和迭代的过程。
我们不禁要问:似乎卷积神经网络设计也不是很复杂,98年就已经有一个比较像样的雏形了。自由换算法和理论证明也没有太多进展。那为什么时隔20年,卷积神经网络才能卷土重来,占领主流?
这一问题与卷积神经网络本身的技术关系不太大,我个人认为与其他一些客观因素有关。
首先,卷积神经网络的深度太浅的话,识别能力往往不如一般的浅层模型,比如SVM或者boosting。但如果做得很深,就需要大量数据进行训练,否则机器学习中的过拟合将不可避免。而2006及2007年开始,正好是互联网开始大量产生各种各样的图片数据的时候。
另外一个条件是运算能力。卷积神经网络对计算机的运算要求比较高,需要大量重复可并行化的计算,在当时CPU只有单核且运算能力比较低的情况下,不可能进行个很深的卷积神经网络的训练。随着GPU计算能力的增长,卷积神经网络结合大数据的训练才成为可能。
最后一点就是人和。卷积神经网络有一批一直在坚持的科学家(如Lecun)才没有被沉默,才没有被海量的浅层方法淹没。然后最后终于看到卷积神经网络占领主流的曙光。
计算机视觉中比较成功的深度学习的应用,包括人脸识别,图像问答,物体检测,物体跟踪。
这里说人脸识别中的人脸比对,即得到一张人脸,与数据库里的人脸进行比对;或同时给两张人脸,判断是不是同一个人。
这方面比较超前的是汤晓鸥教授,他们提出的DeepID算法在LWF上做得比较好。他们也是用卷积神经网络,但在做比对时,两张人脸分别提取了不同位置特征,然后再进行互相比对,得到最后的比对结果。最新的DeepID-3算法,在LWF达到了99.53%准确度,与肉眼识别结果相差无几。
这是2014年左右兴起的课题,即给张图片同时问个问题,然后让计算机回答。比如有一个办公室靠海的图片,然后问“桌子后面有什么”,神经网络输出应该是“椅子和窗户”。
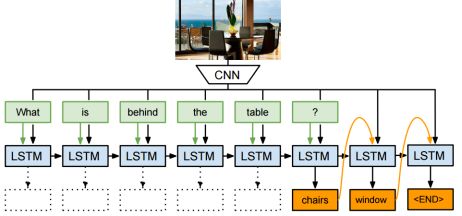
这一应用引入了LSTM网络,这是一个专门设计出来具有一定记忆能力的神经单元。特点是,会把某一个时刻的输出当作下一个时刻的输入。可以认为它比较适合语言等,有时间序列关系的场景。因为我们在读一篇文章和句子的时候,对句子后面的理解是基于前面对词语的记忆。
图像问答问题是基于卷积神经网络和LSTM单元的结合,来实现图像问答。LSTM输出就应该是想要的答案,而输入的就是上一个时刻的输入,以及图像的特征,及问句的每个词语。
深度学习在物体检测方面也取得了非常好的成果。2014年的Region CNN算法,基本思想是首先用一个非深度的方法,在图像中提取可能是物体的图形块,然后深度学习算法根据这些图像块,判断属性和一个具体物体的位置。
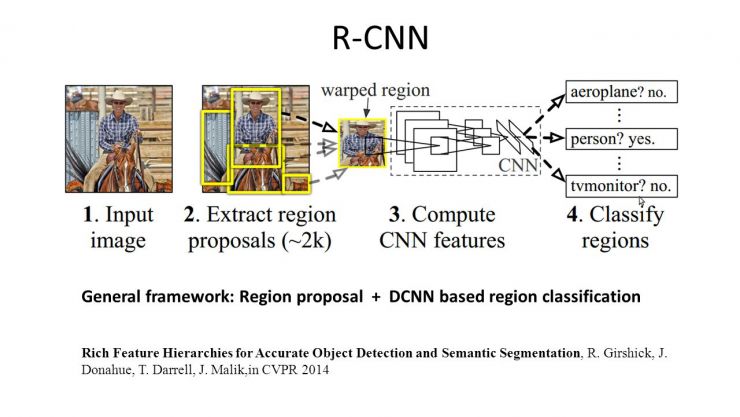
为什么要用非深度的方法先提取可能的图像块?因为在做物体检测的时候,如果你用扫描窗的方法进行物体监测,要考虑到扫描窗大小的不一样,长宽比和位置不一样,如果每一个图像块都要过一遍深度网络的话,这种时间是你无法接受的。
所以用了一个折中的方法,叫Selective Search。先把完全不可能是物体的图像块去除,只剩2000左右的图像块放到深度网络里面判断。那么取得的成绩是AP是58.5,比以往几乎翻了一倍。有一点不尽如人意的是,region CNN的速度非常慢,需要10到45秒处理一张图片。
而且我在去年NIPS上,我们看到的有Faster R-CNN方法,一个超级加速版R-CNN方法。它的速度达到了每秒七帧,即一秒钟可以处理七张图片。技巧在于,不是用图像块来判断是物体还是背景,而把整张图像一起扔进深度网络里,让深度网络自行判断哪里有物体,物体的方块在哪里,种类是什么?
经过深度网络运算的次数从原来的2000次降到一次,速度大大提高了。
Faster R-CNN提出了让深度学习自己生成可能的物体块,再用同样深度网络来判断物体块是否是背景?同时进行分类,还要把边界和给估计出来。
Faster R-CNN可以做到又快又好,在VOC2007上检测AP达到73.2,速度也提高了两三百倍。
YOLO
去年FACEBOOK提出来的YOLO网络,也是进行物体检测,最快达到每秒钟155帧,达到了完全实时。它让一整张图像进入到神经网络,让神经网络自己判断这物体可能在哪里,可能是什么。但它缩减了可能图像块的个数,从原来Faster R-CNN的2000多个缩减缩减到了98个。
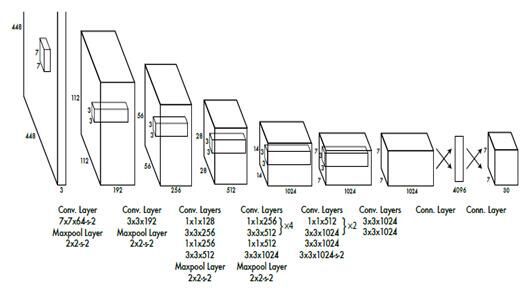
同时取消了Faster R-CNN里面的RPN结构,代替Selective Search结构。YOLO里面没有RPN这一步,而是直接预测物体的种类和位置。
YOLO的代价就是精度下降,在155帧的速度下精度只有52.7,45帧每秒时的精度是63.4。
在arXiv上出现的最新算法叫Single Shot MultiBox Detector,即SSD。
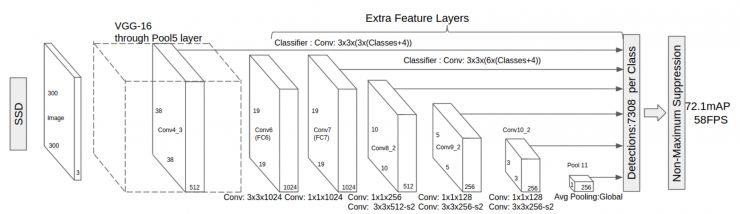
它是YOLO的超级改进版,吸取了YOLO的精度下降的教训,同时保留速度快的特点。它能达到58帧每秒,精度有72.1。速度超过Faster R-CNN 有8倍,但达到类似的精度。
所谓跟踪,就是在视频里面第一帧时锁定感兴趣的物体,让计算机跟着走,不管怎么旋转晃动,甚至躲在树丛后面也要跟踪。
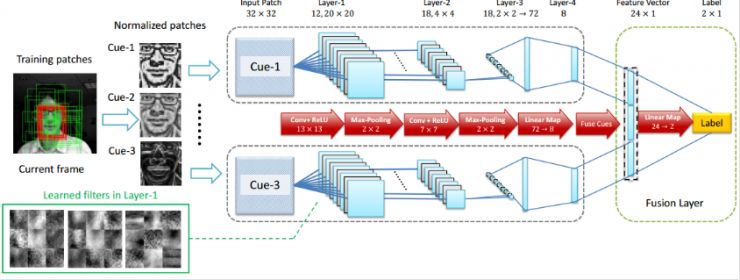
深度学习对跟踪问题有很显著的效果。DeepTrack算法是我在澳大利亚信息科技研究院时和同事提出的,是第一在线用深度学习进行跟踪的文章,当时超过了其它所有的浅层算法。
今年有越来越多深度学习跟踪算法提出。去年十二月ICCV 2015上面,马超提出的Hierarchical Convolutional Feature算法,在数据上达到最新的记录。它不是在线更新一个深度学习网络,而是用一个大网络进行预训练,然后让大网络知道什么是物体什么不是物体。
将大网络放在跟踪视频上面,然后再分析网络在视频上产生的不同特征,用比较成熟的浅层跟踪算法来进行跟踪,这样利用了深度学习特征学习比较好的好处,同时又利用了浅层方法速度较快的优点。效果是每秒钟10帧,同时精度破了记录。
最新的跟踪成果是基于Hierarchical Convolutional Feature,由一个韩国的科研组提出的MDnet。它集合了前面两种深度算法的集大成,首先离线的时候有学习,学习的不是一般的物体检测,也不是ImageNet,学习的是跟踪视频,然后在学习视频结束后,在真正在使用网络的时候更新网络的一部分。这样既在离线的时候得到了大量的训练,在线的时候又能够很灵活改变自己的网络。
回到ADAS问题(慧眼科技的主业),它完全可以用深度学习算法,但对硬件平台有比较高的要求。在汽车上不太可能把一台电脑放上去,因为功率是个问题,很难被市场所接受。
现在的深度学习计算主要是在云端进行,前端拍摄照片,传给后端的云平台处理。但对于ADAS而言,无法接受长时间的数据传输的,或许发生事故后,云端的数据还没传回来。
那是否可以考虑NVIDIA推出的嵌入式平台?NVIDIA推出的嵌入式平台,其运算能力远远强过了所有主流的嵌入式平台,运算能力接近主流的顶级CPU,如台式机的i7。那么慧眼科技在做工作就是要使得深度学习算法,在嵌入式平台有限的资源情况下能够达到实时效果,而且精度几乎没有减少。
具体做法是,首先对网络进行缩减,可能是对网络的结构缩减,由于识别场景不同,也要进行相应的功能性缩减;另外要用最快的深度检测算法,结合最快的深度跟踪算法,同时自己研发出一些场景分析算法。三者结合在一起,目的是减少运算量,减少检测空间的大小。在这种情况下,在有限资源上实现了使用深度学习算法,但精度减少的非常少。
联系人:徐经理
手机:13907330718
电话:0731-22222718
邮箱:hniatcom@163.com
地址: 湖南省株洲市石峰区联诚路79号轨道智谷2号倒班房6楼603室
 湖南智能-MSN
湖南智能-MSN 湖南智能-Skype
湖南智能-Skype
 湖南智能-阿里
湖南智能-阿里